In this blog, I am going to showcase how HBase tables in Hadoop can be loaded as Dataframe.
Here, we will be creating Hive table mapping to HBase Table and then creating dataframe using HiveContext (Spark 1.6) or SparkSession (Spark 2.0) to load Hive table.
Let us create a table in HBase shell.
Create a table using following command:
hbase(main):002:0> create 'custumer_info', 'customer', 'purchases'
A table has been created with name 'custumer_info' and column families 'customer' and 'purchases'.
The scheme of this table can be checked using the following command:
hbase(main):003:0> describe 'custumer_info'
Let us try inserting some sample data into the table by using the following command:
hbase(main):004:0>put 'custumer_info', '101', 'customer:name', 'Satish'
hbase(main):005:0>put 'custumer_info', '101', 'customer:city', 'Bangalore'
hbase(main):006:0>put 'custumer_info', '101', 'purchases:product', 'Mobile'
hbase(main):007:0>put 'custumer_info', '101', 'purchases:price', '9000'
hbase(main):008:0>put 'custumer_info', '102', 'customer:name', 'Ramya'
hbase(main):009:0>put 'custumer_info', '102', 'customer:city', 'Bangalore'
hbase(main):010:0>put 'custumer_info', '102', 'purchases:product', 'Shoes'
hbase(main):011:0>put 'custumer_info', '102', 'purchases:price', '3500'
hbase(main):012:0>put 'custumer_info', '103', 'customer:name', 'Teja'
hbase(main):013:0>put 'custumer_info', '103', 'customer:city', 'Bangalore'
hbase(main):014:0>put 'custumer_info', '103', 'purchases:product', 'Laptop'
hbase(main):015:0>put 'custumer_info', '103', 'purchases:price', '35000'
We can check the number of records inserted by running the below command:
hbase(main):016:0> count 'custumer_info'
We have successfully created a table in HBase. Now let us check out this data in Spark.
Create a HiveTable mapping to HBase table by using following command:
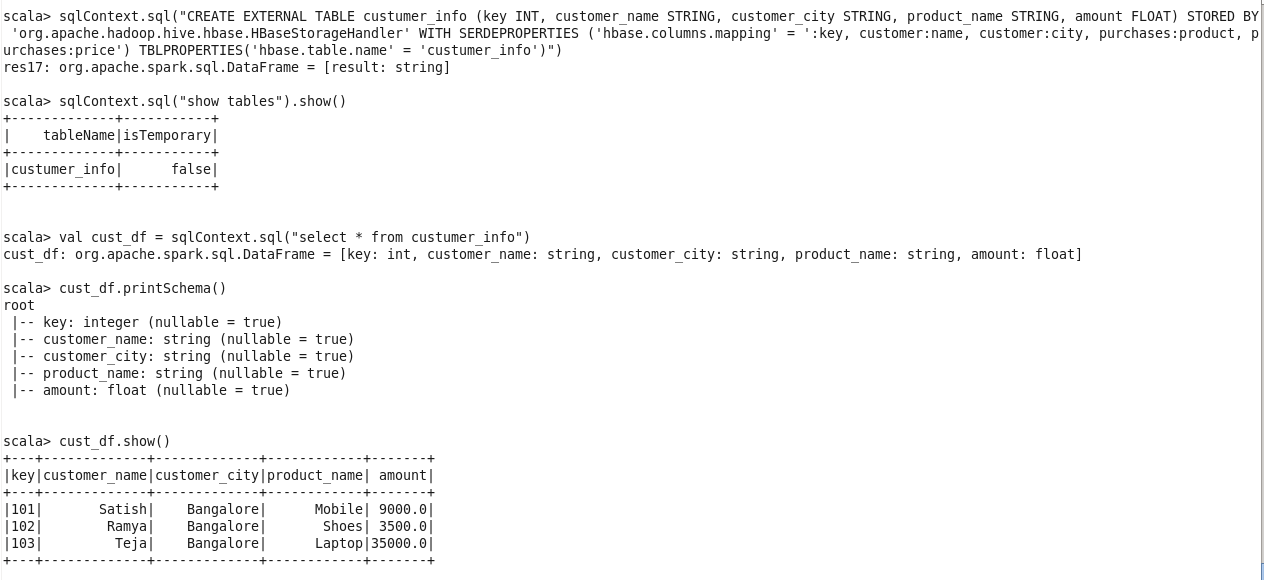
sqlContext.sql("CREATE EXTERNAL TABLE custumer_info (key INT, customer_name STRING, customer_city STRING, product_name STRING, amount FLOAT) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ('hbase.columns.mapping' = ':key, customer:name, customer:city, purchases:product, purchases:price') TBLPROPERTIES('hbase.table.name' = 'custumer_info')")
we can check whether table is create or not by running following command:
hiveContext.sql("show tables").show()
Let us create Dataframe by running the below command:
val cust_df = hiveContext.sql("select * from custumer_info")
Now we have successfully loaded the DataFrame cust_df with the data in the table custumer_info which is in the HBase table.
You can see the DataFrame cust_df schema and contents of the custumer_info table using the DataFrame cust_df by using the following command:
cust_df.printSchema()
cust_df.show()
The whole stack trace is shown in the below screenshot, where you can see that the data in HBase table has been loaded into the Spark DataFrame successfully. Any kinds of operations can be performed on this data.

I hope this blog helped you in understanding the concept in-depth.
Enjoy Spark!
Here, we will be creating Hive table mapping to HBase Table and then creating dataframe using HiveContext (Spark 1.6) or SparkSession (Spark 2.0) to load Hive table.
Let us create a table in HBase shell.
Create a table using following command:
hbase(main):002:0> create 'custumer_info', 'customer', 'purchases'
A table has been created with name 'custumer_info' and column families 'customer' and 'purchases'.
The scheme of this table can be checked using the following command:
hbase(main):003:0> describe 'custumer_info'
Let us try inserting some sample data into the table by using the following command:
hbase(main):004:0>put 'custumer_info', '101', 'customer:name', 'Satish'
hbase(main):005:0>put 'custumer_info', '101', 'customer:city', 'Bangalore'
hbase(main):006:0>put 'custumer_info', '101', 'purchases:product', 'Mobile'
hbase(main):007:0>put 'custumer_info', '101', 'purchases:price', '9000'
hbase(main):008:0>put 'custumer_info', '102', 'customer:name', 'Ramya'
hbase(main):009:0>put 'custumer_info', '102', 'customer:city', 'Bangalore'
hbase(main):010:0>put 'custumer_info', '102', 'purchases:product', 'Shoes'
hbase(main):011:0>put 'custumer_info', '102', 'purchases:price', '3500'
hbase(main):012:0>put 'custumer_info', '103', 'customer:name', 'Teja'
hbase(main):013:0>put 'custumer_info', '103', 'customer:city', 'Bangalore'
hbase(main):014:0>put 'custumer_info', '103', 'purchases:product', 'Laptop'
hbase(main):015:0>put 'custumer_info', '103', 'purchases:price', '35000'
We can check the number of records inserted by running the below command:
hbase(main):016:0> count 'custumer_info'
We have successfully created a table in HBase. Now let us check out this data in Spark.
Create a HiveTable mapping to HBase table by using following command:
sqlContext.sql("CREATE EXTERNAL TABLE custumer_info (key INT, customer_name STRING, customer_city STRING, product_name STRING, amount FLOAT) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ('hbase.columns.mapping' = ':key, customer:name, customer:city, purchases:product, purchases:price') TBLPROPERTIES('hbase.table.name' = 'custumer_info')")
we can check whether table is create or not by running following command:
hiveContext.sql("show tables").show()
Let us create Dataframe by running the below command:
val cust_df = hiveContext.sql("select * from custumer_info")
Now we have successfully loaded the DataFrame cust_df with the data in the table custumer_info which is in the HBase table.
You can see the DataFrame cust_df schema and contents of the custumer_info table using the DataFrame cust_df by using the following command:
cust_df.printSchema()
cust_df.show()
The whole stack trace is shown in the below screenshot, where you can see that the data in HBase table has been loaded into the Spark DataFrame successfully. Any kinds of operations can be performed on this data.
I hope this blog helped you in understanding the concept in-depth.
Enjoy Spark!
Thanks for the good showcase. Is there any performance decrease when accessing hbase data through hive comparing to directly access to hbase?
ReplyDeleteBo
It is nice blog Thank you provide important information and i am searching for same information to save my timeBig data hadoop online Course India
ReplyDeleteBig data in hadoop is the interesting topic and to get some important information. Big data hadoop online training
ReplyDelete